In Part 1 of this series, we drafted an architecture for an end-to-end MLOps pipeline for a visual quality inspection use case at the edge. It is architected to automate the entire machine learning (ML) process, from data labeling to model training and deployment at the edge. The focus on managed and serverless services reduces the need to operate infrastructure for your pipeline and allows you to get started quickly.
In this post, we delve deep into how the labeling and model building and training parts of the pipeline are implemented. If you’re particularly interested in the edge deployment aspect of the architecture, you can skip ahead to Part 3. We also provide an accompanying GitHub repo if you want to deploy and try this yourself.
Solution overview
The sample use case used for this series is a visual quality inspection solution that can detect defects on metal tags, which could be deployed as part of a manufacturing process. The following diagram shows the high-level architecture of the MLOps pipeline we defined in the beginning of this series. If you haven’t read it yet, we recommend checking out Part 1.

Automating data labeling
Data labeling is an inherently labor-intensive task that involves humans (labelers) to label the data. Labeling for our use case means inspecting an image and drawing bounding boxes for each defect that is visible. This may sound straightforward, but we need to take care of a number of things in order to automate this:
- Provide a tool for labelers to draw bounding boxes
- Manage a workforce of labelers
- Ensure good label quality
- Manage and version our data and labels
- Orchestrate the whole process
- Integrate it into the CI/CD system
We can do all of this with AWS services. To facilitate the labeling and manage our workforce, we use Amazon SageMaker Ground Truth, a data labeling service that allows you to build and manage your own data labeling workflows and workforce. You can manage your own private workforce of labelers, or use the power of external labelers via Amazon Mechanical Turk or third-party providers.
On top of that, the whole process can be configured and managed via the AWS SDK, which is what we use to orchestrate our labeling workflow as part of our CI/CD pipeline.
Labeling jobs are used to manage labeling workflows. SageMaker Ground Truth provides out-of-the-box templates for many different labeling task types, including drawing bounding boxes. For more details on how to set up a labeling job for bounding box tasks, check out Streamlining data labeling for YOLO object detection in Amazon SageMaker Ground Truth. For our use case, we adapt the task template for bounding box tasks and use human annotators provided by Mechanical Turk to label our images by default. The following screenshot shows what a labeler sees when working on an image.

Let’s talk about label quality next. The quality of our labels will affect the quality of our ML model. When automating the image labeling with an external human workforce like Mechanical Turk, it’s challenging to ensure a good and consistent label quality due to the lack of domain expertise. Sometimes a private workforce of domain experts is required. In our sample solution, however, we use Mechanical Turk to implement automated labeling of our images.
There are many ways to ensure good label quality. For more information about best practices, refer to the AWS re:Invent 2019 talk, Build accurate training datasets with Amazon SageMaker Ground Truth. As part of this sample solution, we decided to focus on the following:
Finally, we need to think about how to store our labels so they can be reused for training later and enable traceability of used model training data. The output of a SageMaker Ground Truth labeling job is a file in JSON-lines format containing the labels and additional metadata. We decided to use the offline store of Amazon SageMaker Feature Store to store our labels. Compared to simply storing the labels on Amazon Simple Storage Service (Amazon S3), it provides us with a few distinct advantages:
- It stores a complete history of feature values, combined with point-in-time queries. This allow us to easily version our dataset and ensure traceability.
- As a central feature store, it promotes reusability and visibility of our data.
For an introduction to SageMaker Feature Store, refer to Getting started with Amazon SageMaker Feature Store. SageMaker Feature Store supports storing features in tabular format. In our example, we store the following features for each labeled image:
- The location where the image is stored on Amazon S3
- Image dimensions
- The bounding box coordinates and class values
- A status flag indicating whether the label has been approved for use in training
- The labeling job name used to create the label
The following screenshot shows what a typical entry in the feature store might look like.
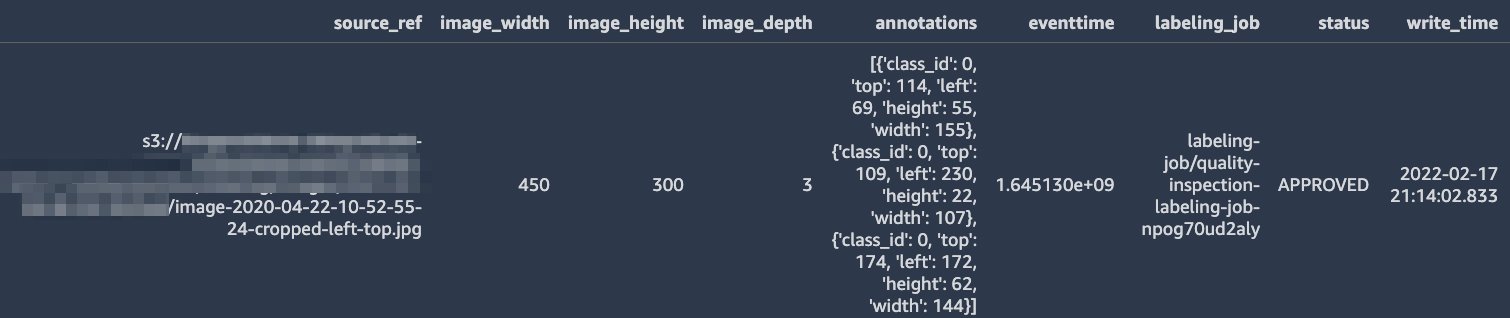
With this format, we can easily query the feature store and work with familiar tools like Pandas to construct a dataset to be used for training later.
Orchestrating data labeling
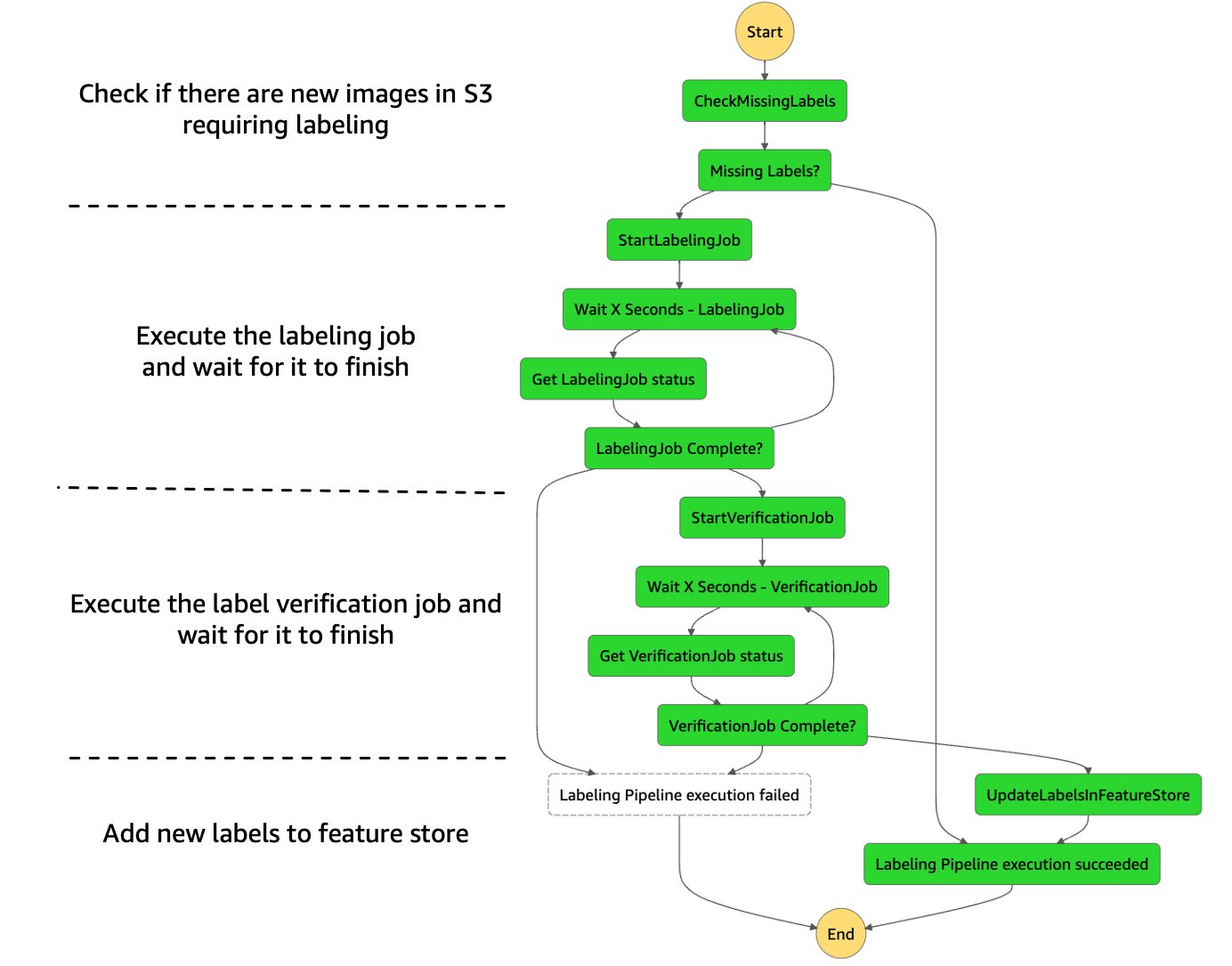
Finally, it’s time to automate and orchestrate each of the steps of our labeling pipeline! For this we use AWS Step Functions, a serverless workflow service that provides us with API integrations to quickly orchestrate and visualize the steps in our workflow. We also use a set of AWS Lambda functions for some of the more complex steps, specifically the following:
- Check if there are new images that require labeling in Amazon S3
- Prepare the data in the required input format and start the labeling job
- Prepare the data in the required input format and start the label verification job
- Write the final set of labels to the feature store
The following figure shows what the full Step Functions labeling state machine looks like.
Labeling: Infrastructure deployment and integration into CI/CD
The final step is to integrate the Step Functions workflow into our CI/CD system and ensure that we deploy the required infrastructure. To accomplish this task, we use the AWS Cloud Development Kit (AWS CDK) to create all of the required infrastructure, like the Lambda functions and Step Functions workflow. With CDK Pipelines, a module of AWS CDK, we create a pipeline in AWS CodePipeline that deploys changes to our infrastructure and triggers an additional pipeline to start the Step Functions workflow. The Step Functions integration in CodePipeline makes this task very easy. We use Amazon EventBridge and CodePipeline Source actions to make sure that the pipeline is triggered on a schedule as well as when changes are pushed to git.
The following diagram shows what the CI/CD architecture for labeling looks like in detail.

Recap automating data labeling
We now have a working pipeline to automatically create labels from unlabeled images of metal tags using SageMaker Ground Truth. The images are picked up from Amazon S3 and fed into a SageMaker Ground Truth labeling job. After the images are labeled, we do a quality check using a label verification job. Finally, the labels are stored in a feature group in SageMaker Feature Store. If you want to try the working example yourself, check out the accompanying GitHub repository. Let’s look at how to automate model building next!
Automating model building
Similar to labeling, let’s have an in-depth look at our model building pipeline. At a minimum, we need to orchestrate the following steps:
- Pull the latest features from the feature store
- Prepare the data for model training
- Train the model
- Evaluate model performance
- Version and store the model
- Approve the model for deployment if performance is acceptable
The model building process is usually driven by a data scientist and is the outcome of a set of experiments done using notebooks or Python code. We can follow a simple three-step process to convert an experiment to a fully automated MLOps pipeline:
- Convert existing preprocessing, training, and evaluation code to command line scripts.
- Create a SageMaker pipeline definition to orchestrate model building. Use the scripts created in step one as part of the processing and training steps.
- Integrate the pipeline into your CI/CD workflow.
This three-step process is generic and can be used for any model architecture and ML framework of your choice. Let’s follow it and start with Step 1 to create the following scripts:
- preprocess.py – This pulls labeled images from SageMaker Feature Store, splits the dataset, and transforms it into the required format for training our model, in our case the input format for YOLOv8
- train.py – This trains an Ultralytics YOLOv8 object detection model using PyTorch to detect scratches on images of metal tags
Orchestrating model building
In Step 2, we bundle these scripts up into training and processing jobs and define the final SageMaker pipeline, which looks like the following figure.

It consists of the following steps:
- A ProcessingStep to load the latest features from SageMaker Feature Store; split the dataset into training, validation, and test sets; and store the datasets as tarballs for training.
- A TrainingStep to train the model using the training, validation, and test datasets and export the mean Average Precision (mAP) metric for the model.
- A ConditionStep to evaluate if the mAP metric value of the trained model is above a configured threshold. If so, a RegisterModel step is run that registers the trained model in the SageMaker Model Registry.
If you are interested in the detailed pipeline code, check out the pipeline definition in our sample repository.
Training: Infrastructure deployment and integration into CI/CD
Now it’s time for Step 3: integration into the CI/CD workflow. Our CI/CD pipeline follows the same pattern illustrated in the labeling section before. We use the AWS CDK to deploy the required pipelines from CodePipeline. The only difference is that we use Amazon SageMaker Pipelines instead of Step Functions. The SageMaker pipeline definition is constructed and triggered as part of a CodeBuild action in CodePipeline.

Conclusion
We now have a fully automated labeling and model training workflow using SageMaker. We started by creating command line scripts from the experiment code. Then we used SageMaker Pipelines to orchestrate each of the model training workflow steps. The command line scripts were integrated as part of the training and processing steps. At the end of the pipeline, the trained model is versioned and registered in SageMaker Model Registry.
Check out Part 3 of this series, where we will take a closer look at the final step of our MLOps workflow. We will create the pipeline that compiles and deploys the model to an edge device using AWS IoT Greengrass!
About the authors
 Michael Roth is a Senior Solutions Architect at AWS supporting Manufacturing customers in Germany to solve their business challenges through AWS technology. Besides work and family he’s interested in sports cars and enjoys Italian coffee.
Michael Roth is a Senior Solutions Architect at AWS supporting Manufacturing customers in Germany to solve their business challenges through AWS technology. Besides work and family he’s interested in sports cars and enjoys Italian coffee.
 Jörg Wöhrle is a Solutions Architect at AWS, working with manufacturing customers in Germany. With a passion for automation, Joerg has worked as a software developer, DevOps engineer, and Site Reliability Engineer in his pre-AWS life. Beyond cloud, he’s an ambitious runner and enjoys quality time with his family. So if you have a DevOps challenge or want to go for a run: let him know.
Jörg Wöhrle is a Solutions Architect at AWS, working with manufacturing customers in Germany. With a passion for automation, Joerg has worked as a software developer, DevOps engineer, and Site Reliability Engineer in his pre-AWS life. Beyond cloud, he’s an ambitious runner and enjoys quality time with his family. So if you have a DevOps challenge or want to go for a run: let him know.
 Johannes Langer is a Senior Solutions Architect at AWS, working with enterprise customers in Germany. Johannes is passionate about applying machine learning to solve real business problems. In his personal life, Johannes enjoys working on home improvement projects and spending time outdoors with his family.
Johannes Langer is a Senior Solutions Architect at AWS, working with enterprise customers in Germany. Johannes is passionate about applying machine learning to solve real business problems. In his personal life, Johannes enjoys working on home improvement projects and spending time outdoors with his family.
